Working With Dataset
On this page, “working with a dataset” refers to “working with rows” of a dataset file loaded into the Project on the Platform.
The ANTAVIRA platform provides the following functionality for working with a dataset:
- Dataset formation;
- Dataset splitter.
Dataset formation
If you need to limit/filter the dataset for modeling according to some conditions, you can use:
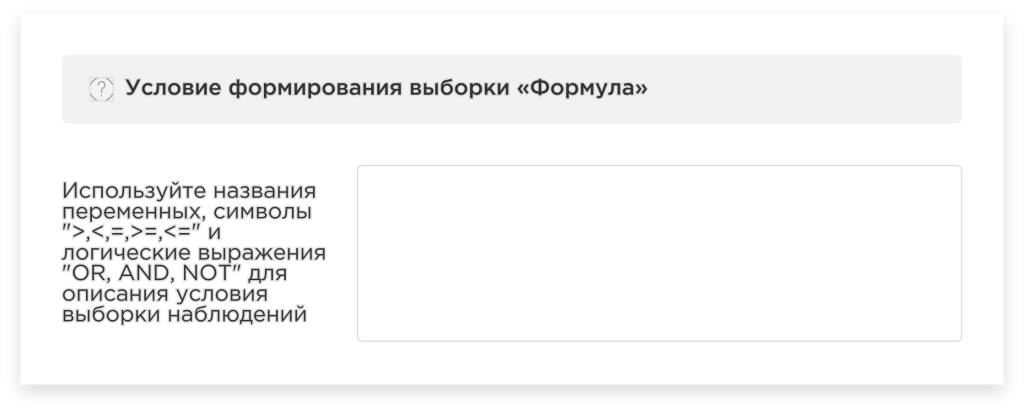
The condition for the dataset formation “Formula”:
In this case, you need to write a formula for the logical expression of the condition. The formula is formed using variables. Then, only those observations, that correspond to the given formula, will participate in the modeling process. In other words, the platform will filter the rows of the entire dataset according to the condition you specify.
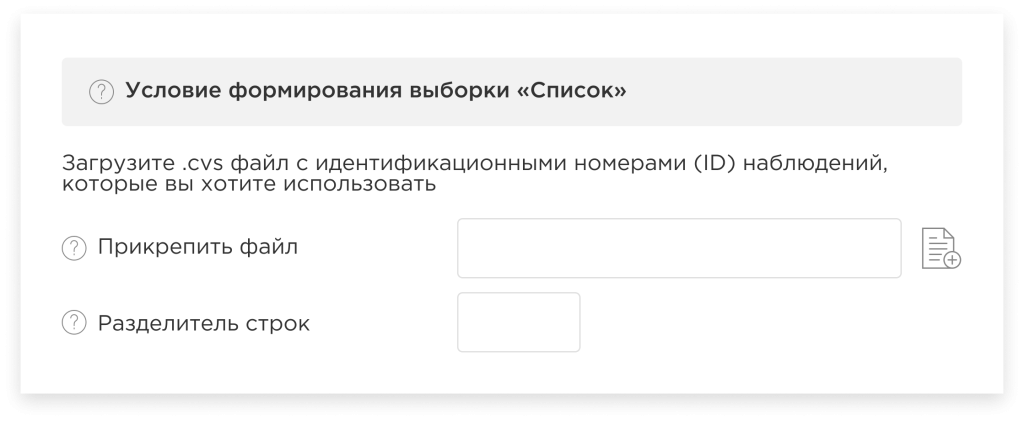
The condition for the dataset formation “List”:
In this case, on the contrary, you need to load a CVS file with the identification numbers of the observations (rows) to be used and specify the row separator. Then only those observations (rows), that correspond to the loaded list, will participate in the modeling process.
If the conditions are not set, then the modeling process will be carried out over the entire dataset.
Dataset splitter
Одновременно с ограничением выборки по какому-либо условию в платформе ANTAVIRA доступен функционал деления выборки на обучающую и тестовую. Соответственно, при работе с выборкой деление реализуется следующими способами, подлежащими гибкой настройке:
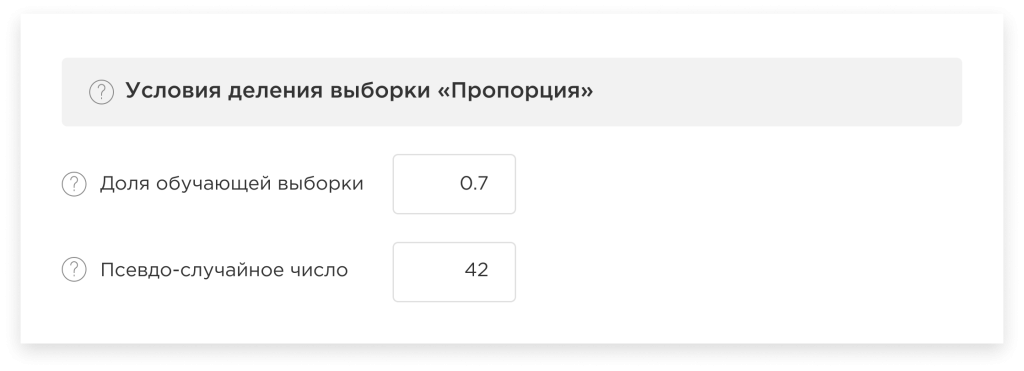
Dataset splitting using the “Proportion” method:
In this case, you can set the proportion of the training set yourself, and the rest part will be used by the platform as a test.
In this case, if at the previous step when forming the graph you specified the sequential use of two splitters, then the results of the first splitting will be the input data for the second splitting. This gives you one training and two test sets, which can improve the reliability and generalization capability of the model, allowing you to more accurately evaluate its performance and detect possible problems, as well as help to ensure that the results are stable and do not depend on a particular dataset.
In addition, you can set a pseudo-random number yourself in order to get a random and balanced split of the data into training and test sets as well as to eliminate possible distortions associated with bias in the data.
Dataset splitting using the “Proportion with sorting” method:
The functionality is under development.
Dataset splitting using the “Time and/or date” method:
The functionality is under development.
Dataset splitting using the “Into equal parts” method:
The functionality is under development.